Cloudflare Down Was a Reminder of How Fragile the Internet Is
When cloudflare down happened it exposed how dependent we are on a few critical systems and why enterprises must rethink resilience
November 19, 2025
5 mins Read
News
The Event That Shook the Internet
When cloudflare down incidents occur, they do more than interrupt a few websites. They ripple through the entire digital ecosystem, affecting services, applications and platforms that rely on Cloudflare’s CDN, DNS and edge network capabilities. Yesterday’s Cloudflare outage demonstrated this clearly. As soon as Cloudflare downtime began, real time monitoring dashboards showed a sudden rise in failures across multiple regions. Websites struggled to load, APIs became unresponsive and login systems across major platforms started to break. Reports from DownDetector and similar trackers indicated a rapid spike in user complaints worldwide, confirming that this was not a local issue but a full scale internet disruption. Cloudflare processes a significant share of global web traffic and even handles more than ten percent of total requests according to publicly referenced data, which means a cloudflare down event instantly becomes a global event capable of slowing the modern web to a crawl.
The impact became more visible as businesses and users tried to navigate the outage. E commerce platforms experienced checkout failures, SaaS tools reported DNS issues, and media services faced intermittent loading problems because Cloudflare’s routing layer was unable to deliver data reliably. Developers noticed API failures and delayed responses from edge functions, while enterprise systems relying on Cloudflare security and caching layers saw latency spikes across their environments. For many users it felt as though large parts of the web simply vanished for a moment, and for organisations it reinforced a harsh reality. A single cloudflare down incident can reveal how concentrated our digital infrastructure has become and how dependent modern enterprises are on a small number of backbone networks. The event was not just another outage but a reminder of how fragile internet scale systems really are and how urgently enterprises must rethink resilience, redundancy and overall architectural preparedness. The problems at Cloudflare come less than a month after outages at other cloud services operators, Amazon’s AWS and Microsoft’s Azure.
Why a Single Cloudflare Failure Creates Global Problems
The most revealing part of the recent cloudflare down event was how quickly it spread across the internet and created issues far beyond Cloudflare’s own systems. Cloudflare sits at the heart of global web infrastructure, handling DNS resolution, CDN delivery, caching, security filtering and routing for millions of websites. When Cloudflare experiences downtime, websites that depend on its network lose access to these critical layers, which immediately affects how they load, respond and authenticate users. Many platforms rely on Cloudflare’s edge servers to deliver content closer to users, and when those servers become unreachable, pages slow dramatically or fail entirely. This explains why a single Cloudflare outage can create widespread internet disruption even if the underlying problem originates from just one part of the network. The scale of Cloudflare’s infrastructure means that cloudflare down events do not stay isolated. They expand rapidly and impact a wide section of the web within minutes.
The outage also highlighted how interconnected modern web services have become. A surprising number of digital products rely on Cloudflare not only for website performance but for essential backend operations such as API traffic, authentication flows, real time data exchange and even mobile app responsiveness. When Cloudflare went down, many of these systems began failing at the same time because their DNS lookups and network routing depended entirely on Cloudflare’s availability. For users, this looked like apps crashing, login pages not loading and checkout systems freezing mid process. For enterprises, this revealed a deeper structural risk. Each cloudflare down incident exposes how reliant modern organisations have become on a small number of shared infrastructure providers. While Cloudflare offers enormous value, the outage demonstrated that even the most resilient platforms can experience failures that ripple across entire markets. This is why enterprises must rethink redundancy and ensure that no single provider becomes a single point of failure in their digital architecture.
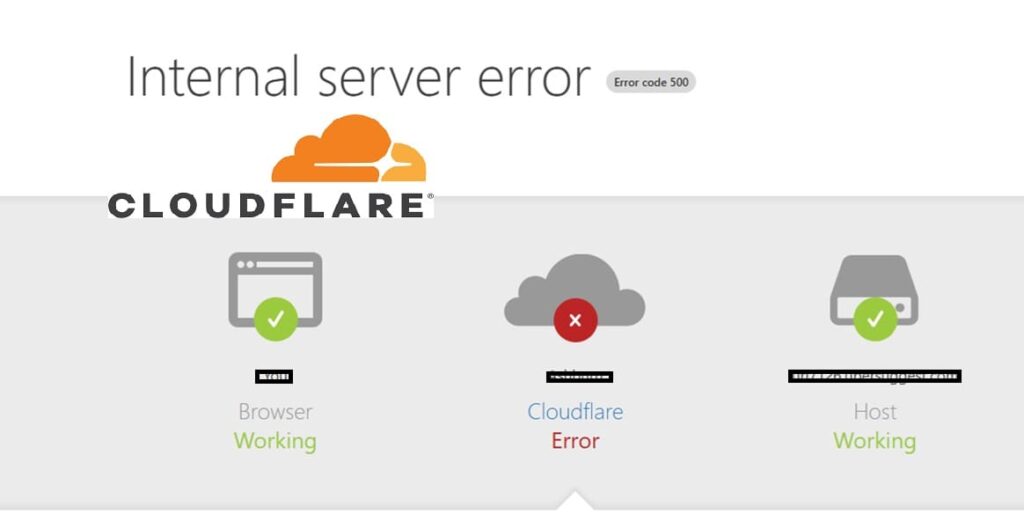
Cloudflare down internal server error screen showing how Cloudflare became the single point of failure during the outage.
Before looking at the broader impact of the cloudflare down event, it helps to see how the outage appeared for millions of users attempting to load websites during the disruption. This visual reflects the exact moment when Cloudflare’s network failed to route traffic, resulting in widespread internal server error messages across the web. This error pattern became common across thousands of platforms, confirming that the outage was not isolated to any specific website. It highlighted how even when user browsers and hosting servers continue to function normally, a cloudflare down incident can interrupt the critical middle layer that keeps the entire internet experience running smoothly.
What the Cloudflare Down Outage Means for Enterprise Risk
The cloudflare down outage made it clear that even the most reliable internet infrastructure providers can become unexpected points of failure. For enterprises, the incident served as a direct reminder that relying heavily on a single CDN, DNS or security platform introduces a form of hidden operational risk that often goes unnoticed until something breaks. Many organisations assume redundancy is built into these global networks, but the outage showed that when a major provider experiences a routing failure or internal error, even well architected systems can become unreachable. During the Cloudflare outage, businesses reported authentication failures, API timeouts and payment processing issues, all because the middle layer that connects users to their applications stopped functioning. This exposed a deeper issue around how dependent modern enterprises have become on shared infrastructure, and how difficult it becomes to maintain continuity when cloudflare down events happen without warning.
Beyond operational disruption, the outage revealed weaknesses in enterprise resilience planning. Some organisations discovered they had no fallback DNS provider or alternative CDN route, which meant their services remained offline until Cloudflare recovered. Others learned that their internal teams lacked visibility into how much of their digital architecture relied on Cloudflare’s edge systems. Even companies with strong engineering teams faced challenges because modern service chains are interconnected through multiple third party components, making it easy to underestimate dependency risk. For enterprises, the cloudflare down incident should not be treated as a one off technical glitch but as a signal that resilience must be intentionally engineered. This includes multi vendor strategies, improved observability, and stronger internal expertise capable of diagnosing outages quickly. The organisations that build these layers of protection are the ones that will remain stable the next time a global provider faces a similar issue.
How Enterprises Can Prepare for the Next Cloudflare Down Event
The cloudflare down outage made it clear that resilience is no longer a luxury for enterprises but a core requirement of modern digital operations. The next failure may come from a DNS provider, a CDN service, an edge network, or even a payment gateway, and the only organisations that continue operating smoothly will be the ones that have built clear redundancy into their architecture. This means using more than one DNS provider, evaluating multi CDN strategies, distributing critical workloads across different cloud regions and ensuring that front end traffic can be rerouted when a major provider encounters an unexpected failure. Preparing for cloudflare down scenarios also involves strengthening internal observability. Teams must be able to identify whether a disruption originates inside their own systems or from an external provider, and they need the capability to switch routes, bypass broken services or temporarily degrade non essential features until the network recovers.
Enterprises must also rethink their talent and architectural readiness. Many organisations discovered during the cloudflare down incident that their internal teams lacked the expertise to understand how deeply their systems were tied to Cloudflare’s layers. Building stronger architectural ownership, investing in network engineers, and documenting end to end traffic flows can significantly reduce downtime during future outages. At a strategic level, leaders should treat the cloudflare down outage as a reminder that resilience depends on intentional design. The internet will always have points of failure, but enterprises can reduce their exposure by planning for redundancy, improving response capabilities, and adopting a mindset where dependency risks are actively monitored rather than assumed to be safe. Protecting the organisation from future outages is not about avoiding Cloudflare or any specific provider. It is about ensuring the business can continue running even when one of the most reliable platforms in the world experiences an unexpected failure.
Why This Outage Should Reshape Enterprise Thinking About Digital Resilience
The cloudflare down incident is a reminder that resilience must be designed intentionally, not assumed through the stability of third party providers. Every enterprise now depends on a complex mesh of digital services that extend far beyond their own applications and infrastructure. Even a brief outage can influence customer experience, platform performance and operational flow, which makes it essential for organisations to treat these disruptions as signals to reassess architectural foundations. Reviewing dependency chains, strengthening redundancy and validating fallback mechanisms are no longer optional tasks. This is where the value of real case studies and practical insights becomes evident, because they reveal how organisations across different industries have navigated similar moments of instability and what design choices protected them from large scale disruption. These references help teams make informed decisions rather than reacting blindly during an outage.
At Yallo, this is the type of work we help enterprises address across resilience planning, architectural clarity and capability development. Many organisations lean on our insights, technical patterns and transformation experience to better understand where their architecture may be overly dependent on a single provider and how they can strengthen their operating model for future outages. Our case studies highlight real scenarios where thoughtful design, distributed systems and stronger capability alignment helped enterprises sustain progress even during major external failures. The cloudflare down event reinforces the need for this level of preparation. Outages are no longer anomalies but expected moments in a highly interconnected digital world. Enterprises that invest in better architecture, stronger resilience strategies and the right talent foundations will be the ones that continue moving forward with confidence, even when the broader internet shows its fragility.